 multirepo.png
multirepo.png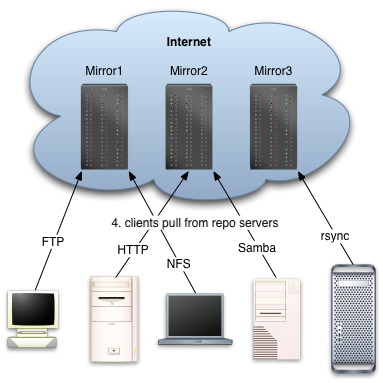 norepo.png
norepo.png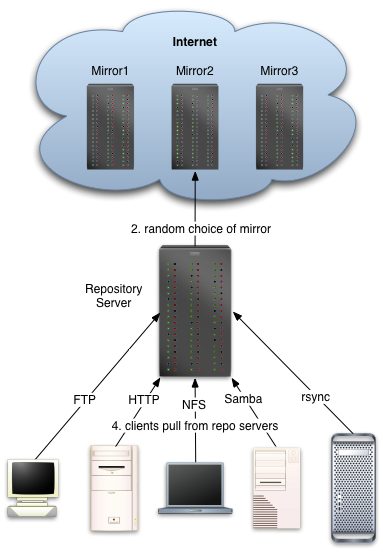 singlerepo.png
singlerepo.png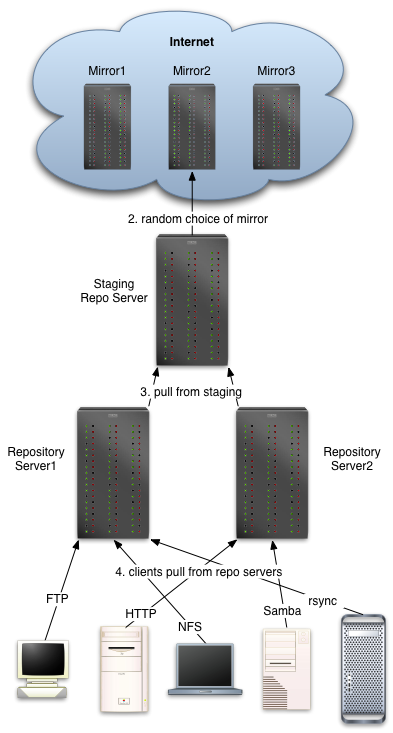 stagingrepo.png
stagingrepo.png| 34297 | Oct 22 | 2005 | ||
| 1309 | Nov 2 | 2005 | ||
| Oct 13 | 2006 | |||
| 20 | May 9 | 06:30 | ||
| 721 | Jul 27 | 2006 | ||
| 34297 | Oct 22 | 2005 | ||
| 29 | May 9 | 06:30 | ||
| 32 | May 9 | 06:30 | ||
| 849 | Sep 22 | 2005 | ||
| multirepo.png | 82292 | Jun 9 | 2005 | |
| norepo.png | 64880 | Jun 9 | 2005 | |
| 7635 | Oct 24 | 2004 | ||
| singlerepo.png | 77403 | Jun 9 | 2005 | |
| stagingrepo.png | 90509 | Jun 9 | 2005 | |
| 214458 | Sep 7 | 21:52 | ||
| 34297 | Oct 22 | 2005 | ||
| 149594 | Aug 30 | 2005 | ||
| 149798 | Sep 14 | 2005 | ||
| 150285 | Sep 17 | 2005 | ||
| 150253 | Sep 17 | 2005 | ||
| 154477 | Oct 10 | 2005 | ||
| 153544 | Oct 10 | 2005 | ||
| 152629 | Oct 11 | 2005 | ||
| 154024 | Oct 22 | 2005 | ||
| 163244 | Oct 22 | 2005 | ||
| 164325 | Nov 2 | 2005 | ||
| 165561 | Nov 3 | 2005 | ||
| 167104 | Jan 31 | 2006 | ||
| 167217 | Jan 31 | 2006 | ||
| 170873 | Feb 1 | 2006 | ||
| 171078 | Feb 3 | 2006 | ||
| 188037 | Feb 11 | 2006 | ||
| 187929 | Feb 14 | 2006 | ||
| 190513 | Feb 20 | 2006 | ||
| 190581 | Mar 21 | 2006 | ||
| 190927 | Mar 21 | 2006 | ||
| 191537 | Mar 21 | 2006 | ||
| 191666 | Mar 21 | 2006 | ||
| 192588 | Apr 2 | 2006 | ||
| 192588 | Apr 13 | 2006 | ||
| 192608 | Apr 18 | 2006 | ||
| 194105 | Apr 18 | 2006 | ||
| 195308 | Apr 21 | 2006 | ||
| 196302 | Apr 25 | 2006 | ||
| 196304 | Apr 26 | 2006 | ||
| 196555 | May 9 | 2006 | ||
| 197773 | May 14 | 2006 | ||
| 202972 | Oct 13 | 2006 | ||
| 205825 | Oct 19 | 2006 | ||
| 205802 | Mar 4 | 2007 | ||
| 214280 | Jun 12 | 23:58 | ||
| 214426 | Jun 13 | 00:27 | ||
| 214421 | Jun 13 | 11:56 | ||
| 214432 | Jun 14 | 20:34 | ||
| 214433 | Jun 19 | 16:04 | ||
| 214445 | Jul 15 | 20:26 | ||
| 214458 | Sep 7 | 21:52 | ||
| 214619 | Sep 7 | 23:14 |
Boldfaced directories have been collapsed into one listing. Click on them to see their contents.




The yum-pull utility pulls down Linux package repositories and stores them on a local drive. Rsync and lftp pull down the files from randomly selected repositories to balance the load. It creates the yum, apt, and up2date headers. The files pulled by this script are re-shared to your rpm-based linux client machines.
The biggest problem we're trying to solve is that multiple client machines all need to get their own updates from Internet mirror sites. Having 3 or 4 machines download a patch isn't bad, but having 30 or 300 is a major waste of bandwidth, both for you and the mirror sites that have to pay for their bandwidth too.
How do your clients get patches and new programs when your line is down? What happens when the mirror site you use is down, or has outdated RPMs or index files?
Yum-pull handles these problems, providing a software install and patching system that scales as you add client machines. From a single collection of downloaded RPMs it can provide repositories in formats compatible with all the major rpm installation tools.
It also provides access to a vast collection of add-on packages available from independant maintainers (for Fedora core 3, the combined collection is over 8200 different packages).
This document is long, but it's trying to cover a lot of things you may already know, such as setting up a web or ftp server or using bind mounts. If you're looking to set up a repository mirror as quickly as possible:
As of version 1.45, it supports the following specific distributions:
For all the above distributions, you can select any or all or the following modules (not all modules available for all distributions): atrpms, biorpms, ccrma, core (original packages from Centos, Fedora, Mandrake, Redhat, Novell/SuSE, or Whitebox distributions), dag, dries, extras, freshrpms, jpackage, kde-redhat-stable, kde-redhat-testing, kde-redhat-unstable, livna (livna, livna-testing, and livna-unstable), local (packages you maintain locally), newrpms, nrpms, openpkg, updates (updates to core), wstearns, and ximian. Also, there are the following macros: "allmodules" (a shorthand for all of the above, and the default if no explicit modules are requested), "allmodulesbutcore", "coreandupdates", and "combinedrepo" (files from all other modules).
To make it easier to create yum.conf files for the clients, it creates yum.conf.addme's for each module in the top level directory of the mirror. If the freedups utility is installed, it also hardlinks identical files (saving 20% to 50% of space requirements).
yum-pull
yum-pull core freshrpms fc_1_i386 /home/repomirror/ ftp://repomirror.myco.com/repomirror/
Here are the steps.
If you'd prefer to have a non-linux machine be the repository mirror, you should be able to do that (I haven't tried it, but it should work). As long as it has the needed tools from above and the "bash" shell to run yum-pull, you should be able to host the content on any OS. If your preference is windows, you might want to look at the www.cygwin.com utilities, as this tool collection provides all of the tools you'll need. If your preference is one of the BSD operating systems, those should come with all the tools you need.
yum-pull fc_3_x86_64 su_9.2_i386 updates core /home/repomirror/ http://repomirror.myco.com/repomirror/
If you want to limit the amount of bandwidth that will be used at any one time, you can specify the maximum bandwidth in kilobytes per second by adding:
bwlimit 40
which would limit the amount of bandwidth used to approximately 40 kilobytes per second, or around 320 kilobits per second.
The last bit on the command line, "http://repomirror.myco.com/yum/" is how a client machines sees the files we'll be downloading. If a client typed that into a browser, they should see the directories "centos", "fedora", "mandrake", etc.
We'll actually get to how to setup the ftp, http, and/or file server(s) in a little bit, but for the moment put in one or more URIs right on the command line, most preferred first:
yum-pull ... http://repomirror.myco.com/repomirror/ ftp://repomirror.myco.com/pub/repomirror/ file:///mnt/repomirror/
Downloading all those RPMs can be severely time and bandwidth comsuming. If you have a number of the RPMs already, you can copy them into the repository space, saving time on the main downloads. First, create the directory tree with the following command:
yum-pull fc_3_x86_64 su_9.2_i386 updates core /home/repomirror/ http://repomirror.myco.com/repomirror/ --nolock --nodownload --noindex
This skips the actual Internet downloads and repository indexing, leaving just the step of creating the directory structure. Once this is done, copy any non-src RPMs you have into the appropriate directories. For example, if you have the RPMs for Fedora linux 3 (x86_64), copy these into /home/repomirror/fedora/linux/3/x86_64/core/packages/ . Don't worry if you don't have them all or your collection is out of date. Copy in what you have and yum-pull will get the rest.
To get the system to automatically pull down and index new rpms with no human intervention, we'll run the script from cron. First, decide which user should be used to download the rpms. This should not be root; there's no advantage and that's a security risk. Lets say the script will be run as the user "mirror":
adduser mirror chown -R mirror.mirror /home/repomirror/ touch /var/spool/cron/mirror
Now bring up /var/spool/cron/mirror with your favorite editor and add something like the following line (I'll wrap it to make it fit on a page, but all of the following needs to be on one line):
9 1,5,11,16 * * * sleep $[ $RANDOM / 32 ] ; yum-pull fc_3_x86_64 su_9.2_i386 updates core /home/repomirror/ bwlimit 40 http://repomirror.myco.com/repomirror/
The sleep command at the beginning pauses this cron job for a random number of seconds between 0 and 1024 ($RANDOM goes up to 32768). This makes the cron job wait for 0-17 minutes (with an average of 8) so not every server storms in at exactly 9 minutes past the hours of 1AM, 5AM, 11AM, and 4PM.
If you find that even a bandwidth-limited pull hurts latency or available bandwidth, you can certainly schedule this for off hours downloading, perhaps even just once a day. As a courtesy to the people who provide the mirrors, I'd suggest not running this more than 4 times a day.
Once you've saved your new cron job, exit your editor and run:
touch /var/spool/cron
Which tells the cron daemon to reread its configuration files.
Once the yum server has the rpm files, it needs to share them with the client machines. This can be done with ftp, http, or any approach that can share files over a network (nfs, samba, afs, lustre, coda or others).
If you haven't already installed it, put in the ftp server software. We'll use vsftpd for this example, though any ftp server will do.
yum install vsftpd
Once vsftpd is running ("/etc/init.d/vsftpd start"), you need the yum files to show up in its publicly shared hierarchy of folders (/var/ftp/pub, by default). Unfortunately, the large block of files currently lives in /home/repomirror/ and we don't want to have to make two copies of the files and waste a lot of drive space and have to keep the copies synchronized.
Current linux kernels allow a tree of files in one place (such as /home/repomirror/) to show up in a completely different location in the namespace (such as /var/ftp/pub/repomirror/) with a technique called "bind mounts". Normal mounts turn an existing block device into a tree of files with the help of filesystem code. Bind mounts simply make an already existing tree of files show up in a new place as well as the original spot.
First, make the directory where the files need to show up:
mkdir -p /var/ftp/pub/repomirror
Next, add a line to /etc/fstab to tell the kernel what tree needs to be republished, and where it should also be seen:
/home/repomirror/ /var/ftp/pub/repomirror/ none bind,nodev,nosuid,noatime 0 0
Now mount this with:
mount /var/ftp/pub/repomirror/
The files that really live in /home/repomirror/ will also show up in /var/ftp/pub/repomirror/ (without taking twice the space).
For reference, nodev and nosuid tell the kernel to ignore any device nodes and setuid bits in the tree respectively. noatime tells the kernel to not be constantly updating the "accessed" bit on files everytime a file is viewed (which saves a noticeable amount of writes on a large repository).
If you haven't already installed it, put in the web server software. We'll use Apache for this example, though any web server will do.
yum install httpd
Now tell Apache what directory to publish. Make a file called /etc/httpd/conf.d/yum.conf with the following content:
Alias /repomirror /home/repomirror <Directory /home/repomirror> Options Indexes FollowSymLinks MultiViews AllowOverride None Order allow,deny #Allow from 172.16 127.0.0.1 #Deny from all </Directory>
If uncommented, the last two lines only serve up the yum tree to localhost and the 172.16.0.0/16 network; if you choose to restrict access to this server, adjust the 172.16 to match your network address.
Once the configuration is finished, restart the web server with:
/etc/init.d/httpd restart
and check for errors in /var/log/httpd/access.log and /var/log/httpd/error.log .
As a test, go to a client machine and try to view http://repomirror.myco.com/repomirror/; you should see the top-level directories like centos, fedora, mandrake, etc. on this page.
If the machine repomirror.myco.com already shares files with the client machines, we can use this filesharing to publish the files out to the clients. Any type of fileshare works: NFS, Samba/Windows file sharing, Coda, Intermezzo, Lustre, AFS, or anything else.
When you set up the file share, it's a good idea to make this a read-only share (so the clients can't accidentally or maliciously modify the packages or indexes).
Once the share is set up (let's say the files are mounted on /mnt/repomirror/), you can use URIs like "file:///mnt/repomirror/" instead of, or in addition to traditional URIs like "http://repomirror.myco.com".
One really nice feature of this approach if you're using yum is that you can bind mount the exact tree of file you need under /var/cache/yum/ . Let's say this particular machine is a Fedora core 2/i386 system and that you're mounting the repository mirror under /mnt/repomirror/ . Edit /etc/fstab and add a line like this:
/mnt/repomirror/fedora/linux/2/i386/ /var/cache/yum/ none bind,nodev,nosuid,noatime 0 0
The files you need are already in place for yum to use. Remember to update that line in /etc/fstab when you update to a new version of your Linux distribution.
None of the client tools directly use rsync, so this is more for sharing files between multiple repository mirror machines.
Install the rsync package if it's not already installed. Now create the configuration file ( /etc/rsyncd.conf ) that tells rsync what to share and how:
#motd file = /home/rsyncd.motd #log file = /home/rsyncd.log use chroot = true read only = true uid = nobody gid = nobody transfer logging = true timeout = 600 #Repository mirror [repomirror] path = /home/repomirror comment = Repository mirror
If you choose to uncomment the "motd file =" line, it will show a short text message to people who connect, perhaps telling them what this server is for, general system policy, and contact information in case they encounter problems. Here's a sample; customize for your site:
---- This is the Myco.com rsync server. This site is provided solely for the purpose of anonymous downloads of certain predefined content areas. Any other use is forbidden. Please direct questions to [email protected]. ----
If you uncomment the "log file =" line, rsync will write a 2 line summary of each file transferred to that log file.
Now modify the "disable =" line in /etc/xinetd.d/rsync so it ends up reading
disable = no
and restart xinetd with:
/etc/init.d/xinetd reload
To test that the rsync server is working, go to another machine and run:
rsync rsync://machine_name_or_ip/repomirror/
and you should get a directory listing of the available general distributions.
More info: man page for rsyncd.conf.
Now that you have the downloads started, let's set up the client systems. The setup is different for each software installation tool, but we have instructions for yum, apt, and up2date. Any tool compatible with these (like opencarpet, red-carpet, synaptic, and yumi) should just work with the changes you'll make in the following sections.
You can use any mix of client applications over your client machines you want. That said, I would discourage using multiple software install programs on a single machine. At one point I used two different install tools around the same time and lost my rpm database (although that might just have been coincidental with a now-fixed locking bug).
To see if yum is available on a system, type
yumor look for a file /etc/yum.conf .
If a given client system uses yum, you'll just need to know the top-level url of your repository and what general distribution the machine is using. In this example, we'll assume your repository tree starts with http://repomirror.myco.com/yum/ and that this machine uses mandrake linux. In this case, pull down the automatically generated configuration block with:
wget http://repomirror.myco.com/repomirror/mandrake/yum.conf.addme
If wget isn't available, any web download tool will do: lynx, lftp, links, netscape, mozilla, firefox, and, in a pinch, nc or telnet. :-)
Once you've saved this block to disk, append its contents to /etc/yum.conf . /etc/yum.conf (and/or the files in /etc/yum/repos.d ) may contain other repository blocks (lines starting with "[repo_name]"). You'll probably want to comment these out (the point of setting up a local repository mirror is to avoid using these Internet servers), except for the block called "[main]" which holds global settings for the yum program.
To actually update packages, run:
yum update
This will give you a list of packages to be installed or upgraded and will ask you to confirm with a "y".
If your system has the file /etc/cron.daily/yum.cron, it will start automatically installing updates tomorrow morning. Otherwise, you can add the following line to root's cron file (/var/spool/cron/root) and "touch /var/spool/cron":
30 3 * * * sleep $[ $RANDOM / 32 ] ; yum -y updateWe're running this at a random number of seconds after 3:30AM - enough time for the repository server to finish downloading and indexing the files before the client machines start.
To see if apt is on the system, try running "apt" or look for the file /etc/apt/sources.list .
yum-pull needs to create configuration blocks for specific distributions such as "Fedora core 3 for i386", as opposed to yum where one yum.conf.addme applies for all fedora distributions. The url you'll need to get has this form:
{URI starting point}/{distribution}/linux/{version}/{arch}/sources.list.addme
For Fedora core 3, i386, and our repomirror machine, this would be:
http://repomirror.myco.com/repomirror/fedora/linux/3/i386/sources.list.addme
Pull this down with wget or any other web browsing program and append the contents to /etc/apt/sources.list . You may wish to comment out other remote repositories in favor of your local one (the point of setting up a local repository mirror is to avoid using these Internet servers).
To update packages with apt, you need to run two steps:
apt-get update apt-get upgrade
The first synchronizes the indexes with those on the repository server. The second actually installs new versions of installed packages.
To have this happen automatically in the middle of the night you can add the following line to root's cron file (/var/spool/cron/root) and "touch /var/spool/cron":
30 3 * * * sleep $[ $RANDOM / 32 ] ; apt-get update ; apt-get -y upgradeAgain, run this after the repository server has had a chance to download and index the rpms. The "-y" does the same here as for apt; it answers "yes" to all non-critical prompts.
To see if up2date is installed try running "up2date" from the command line or look for /etc/sysconfig/rhn/sources .
Like the apt section above, you'll need to figure out which specific distribution you're using. Once you know that, you'll get a slightly different file from the same directory off your repository server:
http://repomirror.myco.com/repomirror/fedora/linux/3/i386/sources.addme
Download this with a web browser or download tool and append the contents of this to /etc/sysconfig/rhn/sources . You may wish to comment out other sources in favor of these new lines for the local repository server (the point of setting up a local repository mirror is to avoid using these Internet servers).
The rpm command doesn't know how to use the dependency information provided by the apt and yum indexes, so you still have to manually add required rpms to the command line. That said, it does at least have the ability to pull down files from http and ftp servers, so you can run commands like this:
rpm -Uvh http://repomirror.myco.com/repomirror/fedora/linux/3/i386/updates/packages/grep-2.5.1-31.4.i386.rpm
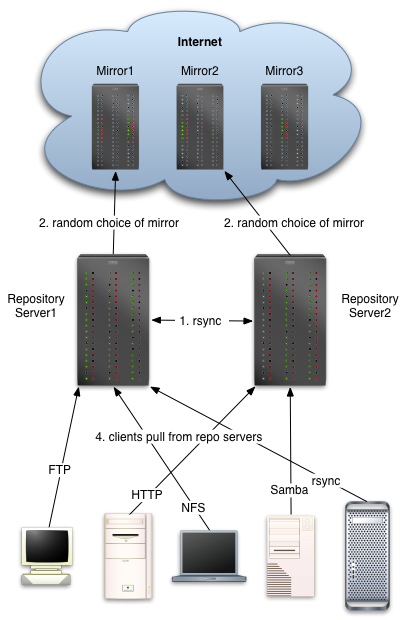
If you are supporting enough client machines that you need to scale to more repository servers (or simply want to always have redundant servers), we can set up more than one with the layout to the right.
While we could just set up multiple servers just like described above, we can also teach our repository servers to check with each other first before heading out to the Internet to pull down files; this means that any given file should only be downloaded once no matter how many repository servers you have.
There are two minor changes to make to the above setup. First, we'll set up a DNS name ("repomirror") that randomly resolves to both machines (called round-robin DNS). Lets assume the first repository server is called "bart.myco.com" and the second is "lisa.myco.com". We'll add lines like these to our DNS data:
repomirror.myco.com. 7200 IN CNAME bart.myco.com. repomirror.myco.com. 7200 IN CNAME lisa.myco.com.
Update the DNS serial number, reload the dns data, and try:
ping repomirror.myco.com
Run this command multiple times; about half of the time it should ping bart, and about half of the time it should ping lisa.
Now, change any references to specific machines over to the new "repomirror.myco.com". In particular, change the yum-pull command line and any client configuration files to use repomirror.
The second step is to tell bart and lisa to check with each other before heading out to bother the overloaded Internet mirrors. Any files they can get from each other are files that don't have to travel over your link twice. To do this, set up an anonymous rsync server on both bart and lisa.
Once that's done, we'll edit the cron line. Here's how it used to look (line wrapped):
9 1,5,11,16 * * * sleep $[ $RANDOM / 32 ] ; yum-pull fc_3_x86_64 su_9.2_i386 updates core /home/repomirror/ bwlimit 40 http://repomirror.myco.com/repomirror/
We'll stagger the downloads and have each machine check with the other. Here's Bart's new line (make sure it's one line in the crontab):
9 1,5,11,16 * * * sleep $[ $RANDOM / 32 ] ; rsync -aH --partial --exclude-from=/home/repomirror/master-exclude --exclude-from=/home/repomirror/general-exclude --ignore-existing --timeout=300 rsync://lisa.myco.com/repomirror/ /home/repomirror/ ; yum-pull fc_3_x86_64 su_9.2_i386 updates core /home/repomirror/ bwlimit 40 http://repomirror.myco.com/repomirror/
, and here's Lisa's (make sure it's one line in the crontab):
9 2,6,12,17 * * * sleep $[ $RANDOM / 32 ] ; rsync -aH --partial --exclude-from=/home/repomirror/master-exclude --exclude-from=/home/repomirror/general-exclude --ignore-existing --timeout=300 rsync://bart.myco.com/repomirror/ /home/repomirror/ ; yum-pull fc_3_x86_64 su_9.2_i386 updates core /home/repomirror/ bwlimit 40 http://repomirror.myco.com/repomirror/
For 3 or more repository servers, we follow the same approach: we stagger the start times so we don't simultaneously mob the Internet mirrors and each machine synchronizes with the peer mirror that last went out to the Internet.
In some environments, the system administrators of the Linux machines don't want to blindly trust the people supplying the RPMs. For example, if I ran a web server that was critical to the operation of my business, I might want to test any new packages on an identical test web server to make sure that the new packages won't break any scripts or functionality.
By itself, yum won't do this. But it certainly is possible to do this by adjusting the download process a little bit.
rsync -aH --partial --timeout=300 rsync://marge.myco.com/repomirror/ /home/repomirror/
Both Bart and Lisa will pull down Marge's tree verbatim, including the indexes Marge already built.
Here's the file layout:
/home/repomirror
`-- fedora
`-- linux
|-- 1
| |-- i386
| | |-- atrpms
| | | |-- headers
| | | |-- packages
| | | `-- repodata
| | |-- ccrma
| | | |-- headers
| | | |-- packages
| | | `-- repodata
| | |-- core
| | | |-- headers
| | | |-- packages
| | | `-- repodata
| | |-- dag
| | | |-- headers
| | | |-- packages
| | | `-- repodata
| | |-- freshrpms
| | | |-- headers
| | | |-- packages
| | | `-- repodata
| | |-- updates
| | | |-- headers
| | | |-- packages
| | | `-- repodata
| | `-- wstearns
| | |-- headers
| | |-- packages
| | `-- repodata
The actual rpms go in the "packages" directories. "headers" and "repodata" hold the yum metadata (old and new formats, respectively). "redhat" is at the same level as fedora, and the different OS versions are at the same level as "1".
Dag Wieers offers a tool called yam that also pulls down repositories. The two tools have slightly different goals, but both aim to pull down local copies of repositories.
Morten Kjeldgaard provides Repo Janitor with similar goals.
William Stearns wrote the yum-pull tool and this document. Marion Bates was kind enough to provide the network layout images.
Yum-pull depends on a lot of external tools that perform the indexing and maintenance. Many thanks to the authors of these tools for all their work.
The files in this collection are part of William Stearns' software archive. If any of the links on this page do not work, you may be viewing an incomplete mirror. There is a complete list of the mirror sites at the starting page for this mirror and at the primary mirror.